TL;DR
表記揺れがふくまれる検索クエリにマッチしたコンテンツを表示するための手法として、スミス・ウォーターマン法に基づくあいまい検索を実装して検索精度を向上しました。この手法は機械学習システムを使わないためメンテナンスコストが低く、その一方で速度面でも実用的な性能を持ちチューニングしやすいのが特長です。
はじめに
こんにちは、ギフトモールで検索エンジンなどを開発している @samayotta です。
私たちギフトモールはプレゼントに特化したECサービスを提供しています。ギフトECにおいても、ユーザのニーズにマッチする商品を探すための検索機能は重要となります。例えば、弊社が運用しているギフトECサービスの一つであるギフトモールは、ユーザが入力する文字列の検索クエリから関連するキーワードを検出し、そのキーワードに紐づいているコンテンツ(商品、記事、etc.)を提示する検索機能を持っています。
この検索機能において、検索クエリ内の表記揺れに対応することは重要です。ユーザは時に開発者が想定できないような仕方でキーワードを入力します。たとえばブランド名には表記揺れが多く、例えばブランド名 ポール・スミス が ポールスミス として入力されるのは珍しくありません。 それ以外にも、記号や漢字の閉じ開きの違い、単純な入力ミスもたくさん含まれます。このような表記の違いを吸収して、適切なキーワードにクエリをマッチングさせる必要があります。もちろん、完璧な対策はありませんが、 str.Contains のようなナイーブな文字列一致より良い方法を探したいです。
そこで、この記事では、シンプルかつファジーな文字列マッチングを可能にするアルゴリズムについて紹介したいと思います。最初に、クラシカルな最長共通部分列問題を取り上げます。次に、これをより洗練させたスミス・ウォーターマン法による解決法を示しました。
- 本記事は最長共通部分列 (Longest Common Subsequence, LCS)についてちょっと聞いたことがあるという読者を想定しています。
解決したい問題
以下のような関数を作りたいです。
入力
- ユーザクエリ
string - キーワードリスト
string[]- こちらはユーザ入力でなく、システム上で用意します。
出力
- ユーザークエリに含まれるキーワードリスト:
string[]- これは入力のキーワードリストのsubsetです。
- 実際には、これらのキーワードに紐づくコンテンツをユーザに提示します。
出力が満たすべき要件
ユーザクエリからキーワードを取り出せるだけ取り出します。取り出すにあたっては、できるだけ大きいキーワードが取り出せるようにします。厳密には、出力の配列中のキーワードの長さの合計が最も大きくなるように返します。
入力の制約
- ユーザクエリは大部分が日本語です。
- ユーザクエリはスペース区切りの単語列だけでなく、不完全な文や文節の場合があります。
- ユーザクエリはキーワードに対して表記揺れを含む場合があります。
入出力例
例1
user query = "ポール・スミス 財布 父の日" keywords = ["ポール・スミス", "財布", "父の日", "父"] # => ["ポール・スミス", "財布", "父の日"]
「父」よりも長い「父の日」を優先して取ります。
例2
user query = "ポールスミス 財布 父の日" keywords = ["ポール・スミス", "財布", "父の日", "父"] # => ["ポール・スミス", "財布", "父の日"]
ポールスミス は ポール・スミス の表記揺れです。表記揺れには、中黒の他にも、スペース、漢字の閉じ開き、単純な入力ミスなどのケースが考えられます。
例3
user query = "父の日のポールスミスの財布のプレゼントを教えて下さい。" keywords = ["ポール・スミス", "財布", "父の日", "父"] # => ["父の日", "ポール・スミス", "財布"]
入力が文で与えられることもあります。さらに、 ポール・スミス は ポールスミス に表記揺れしています。一見、格助詞 の でsplitするとよさそうですが、 父の日 を優先的にマッチさせたいことを考えるとうまくいかなさそうです。
対応方針の検討
最初に、自明なベースラインとしては、 str.Contains などの文字列マッチングを使う方法があります。またキーワードに表記揺れをカバーしたシノニムを人手で作成し、それをマッチさせると精度が改善できます。しかし、これは人力での編集作業が発生するのでスケールしない解決策です。
次に、機械学習特にニューラルネットワークを用いた最近の自然言語処理を使って実装してみたいという方もいるでしょう。しかし、機械学習システムの重いメンテナンスコストを考えると、小さいチームでは適切でないかもしれません。MeCabのような学習済みでシンプルな形態素解析ライブラリも有効に働く可能性がありますが、それらの学習済みモデルが起こす予測できない挙動を考えると、サービスのコアなビジネスロジックでそれに依存するべきではないと考えられます。
第三に、もう少し複雑な文字列マッチングアルゴリズムを使うことを考えてみます。表記揺れの問題は典型的には編集距離(レーベンシュタイン距離)の考え方で解決できることが知られています。編集距離とは2つの文字列間の距離を、片方を操作して同じものにするためにかかる追加・削除・置換回数によって表したものです。たとえば、 color とcolourの編集距離は、 u を追加する必要があるので 1 となります。ここに小さな閾値を設定し、距離がその閾値よりも小さければ同じものとしてみなせばよさそうです。ただしこのアイデアは、比べる文字列の長さがお互いにだいたい同じような場合でのみうまくいきます。私たちのケースでは、例3のように入力文字列がキーワードよりもはるかに長い場合があります。たとえば、 父の日のポールスミスの財布のプレゼントを教えて下さい。 に対して、 ポール・スミス の編集距離は、左右のいらない部分の文章だけ遠くなってしまいます。
そこで、長い文字列に対してうまくワークするやり方、つまり最長共通部分列を求めるアルゴリズムに帰着させて解くのが良さそうと判断しました。
最長共通部分列問題
最長共通部分列 (Longest Common Subsequence, 以下LCS)とは、二つの文字列のうち、”飛び”を許しつつもっとも長い共通部分を示します。(余談ですが、大学生のころ、筆者はこのLCS問題が得意ではありませんでした。他のアルゴリズム入門講座で取り上げられるものよりも難しく感じられたからです。しかし、入門講座に取り上げられるだけあって、文字列のマッチングを考える上でとても役立つアイデアだと思います。)
ここで、二つの文字列 s と t のLCSを求める関数 LCS を以下のように定義します。
func LCS(s, t string) (lcsLength int, lcsString string)
例えば、文字列 abcdefg と abcdeeeef のLCSは長さ 6 の文字列 abcdef ですが、これをLCS関数を使って表現すると以下のように書けます。
LCS("abcdeeeef", "abcdefg") // => 6, "abcdef"
LCS関数は、存在しない g や重複した e を許容します。ただし、並び順は守られている必要があります。
LCSを使うと、編集距離による解決策に比較して、長い入力文字列に対して頑健な結果を得られます。 LCSの長さ / キーワードの長さ は良い指標として使えそうです。例3で、キーワード ポール・スミス 7文字のうち ポールススミス 6文字が一致します。閾値を仮に 0.8 とおいてやると、 6/7 > 0.8 なのでポール・スミスを採用する、という判断ができます。その後、ユーザ入力文字列から部分文字列分を差し引くと、キーワードをうまく取り尽くせそうです。
実装について検討しましょう。LCSを求める関数 LCS は動的計画法(Dynamic Programming, DP)で実装されます。これが上の例のDPテーブルです。
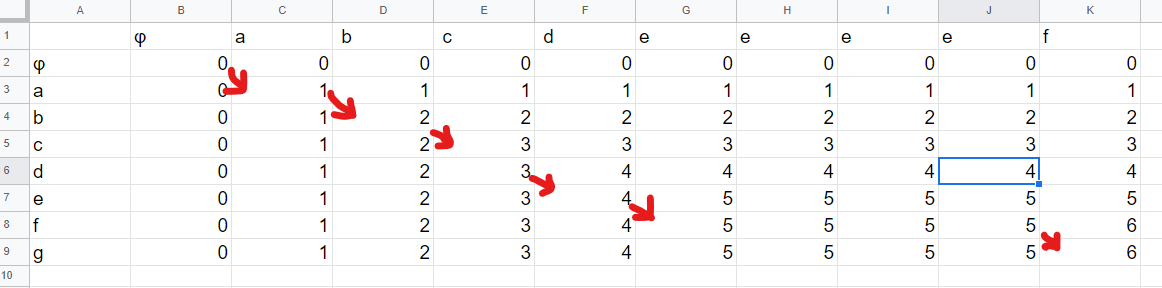
この操作は、こう考えてみるとわかりやすいかもしれません。二つのキュー ["φ", "a", "b", "c", "d", "e", "e", "e", "e", "f"] と ["φ", "a", "b", "c", "d", "e", "f", "g"] を持っていて、両方のキューから同時に文字をpopしそれが等しいなら1点を得られます。キューは片方だけpopすることもできますが、その場合は点数は得られません。ここで先頭の φ は、まだ何も操作をしていない状態を表す記号です。ここで、2つのキューがとりえる状態の組み合わせは、上記のテーブルのマス目分しかないことに気づきます。テーブルのマス目ひとつひとつが、2つのキューの状態と、その状態における点数を表現しています。各状態の移動は、斜め移動は文字一致でのpop、下か右への移動は片方だけのpopに相当します。そして各々のマス目における点数とは、その時点におけるLCSの長さそのものに他なりません。この操作が難しいと感じる人は、スプレッドシートで実際に表を作成し、手計算してみるのが理解の助けになるはずです。
LCSについて紙面の関係上この記事でもっと取り扱うことはできませんが、インターネット上にはたくさんの役立つリソースがあります。日本語の記事では、アルゴ式の説明がおすすめです。
ところで、実際のLCS文字列を取得するためには、作成したテーブルをもう一度後ろから遡る必要があります。同じ長さのLCS文字列は複数通り作れる場合がありますが、今回の場合はやりたいことの趣旨からそのうち1つを調べるだけでよさそうです。
これがGolangによる実装例です。
// ex. ("abcdeeeef", "abcdefg") => 6, "abcdef" func LongestCommonSubsequence(s, t string) (int, string) { sAsRunes := []rune(s) tAsRunes := []rune(t) sLen := len(sAsRunes) tLen := len(tAsRunes) dp := make([][]int, sLen+1) for i := 0; i < sLen+1; i++ { dp[i] = make([]int, tLen+1) } // fill the DP table for i := 1; i <= sLen; i++ { for j := 1; j <= tLen; j++ { if sAsRunes[i-1] == tAsRunes[j-1] { dp[i][j] = dp[i-1][j-1] + 1 } else { dp[i][j] = max(dp[i-1][j], dp[i][j-1]) } } } // construct lcs by backtracking lcsLen := dp[sLen][tLen] lcs := make([]rune, lcsLen) backtrack(sAsRunes, tAsRunes, &dp, sLen, tLen, &lcs, lcsLen) return lcsLen, string(lcs) } func backtrack(s, t []rune, dp *[][]int, i, j int, lcs *[]rune, lcsIndex int) { // basecase if i == 0 || j == 0 { return } if s[i-1] == t[j-1] { backtrack(s, t, dp, i-1, j-1, lcs, lcsIndex-1) (*lcs)[lcsIndex-1] = s[i-1] } else { if (*dp)[i-1][j] >= (*dp)[i][j-1] { backtrack(s, t, dp, i-1, j, lcs, lcsIndex) } else { backtrack(s, t, dp, i, j-1, lcs, lcsIndex) } } } func max(a, b int) int { if a < b { return b } return a }
スミス・ウォーターマン法
ただし、依然としていくつかのコーナーケースが残っています。たとえば、長いユーザー入力においては、あるキーワードに対して偶然長いLCSが取れてしまうケースがあります。
LCS("Time flies like an arrow", "mellow") => "mellow" // tiME fLies Like an arrOW LCS("エルメスのバッグ", "エコバッグ") // => "エバッグ"
閾値が 0.8 のケースでは、5文字中4文字マッチしているエコバッグ は エルメスのバッグ に対して マッチしていることになってしまいます。意図としては、以下のようになっていてほしいです。
("エルメスのバッグ", "エコバッグ") => "バッグ"
スミス・ウォーターマン法は、このような長すぎるギャップや多すぎるミスマッチにペナルティを加え結果を加工する、より洗練されたアルゴリズムです。
この方法によって得られる結果は、共通文字列が両文字列のある領域に絞られることからローカルアラインメント(Local Alignment)と呼ばれ、さまざまな領域で広く使用されています。例えば、コンピュータ生物科学者は二つのDNAコードから局所的な類似性を見出すのに使用しています。他にも、CLIで有名なあいまい検索ツール fzf はこのアルゴリズムに基づいて実装されています。
このアルゴリズムでは、次のような関数 GetLocalAlignment を定義します。
// ex. ("エルメスのバッグ", "エコバッグ", (適切なペナルティ設定)) => "バッグ" func GetLocalAlignment(s, t string, config *LocalAlignmentConfig)
この関数が計算するDPテーブルの例です。

本質的に、これは重み付きのLCSです。
type LocalAlignmentConfig struct { MatchScore int UnmatchPenalty int GapPenalty int }
ここでは三つのハイパーパラメータを定義しています。第一に MatchScore (斜め方向、キューの両方をpopし、文字が一致していたときの得点)、第二に UnmatchPenalty (斜め方向、キューの両方をpopしたが文字が一致していないときのペナルティ)、第三に GapPenalty (下・右方向、片方のキューだけpopしたときのペナルティ)です。LCSのシンプルなルールの代わりに、これらのパラメータを使って状態を遷移します。
ざっくり擬似コードで表すと、 dp[i][j] でのスコアは以下のようになります。
var diagonalScore int if sAsRunes[i-1] == tAsRunes[j-1] { diagonalScore = dp[i-1][j-1] + config.MatchScore // 一致しているときの斜め方向 } else { diagonalScore = dp[i-1][j-1] - config.UnmatchPenalty // 一致していないときの斜め方向 } dp[i][j] = maxOfFour( 0, diagonalScore, // 斜め方向 dp[i-1][j]- config.GapPenalty, // 下方向 dp[i][j-1]- config.GapPenalty, // 右方向 )
スコアが0より大きい、もっとも長い系列が見つかったら、それがローカルアラインメントを示しています。補足ですが、ローカルアラインメントの実際の文字列を求めるには、最も点数の高い場所から遡る必要があります。
ところで、適切なスコアセットは自分で探索して見つける必要があります。
config := util.NewLocalAlignmentConfig(3, 3, 2) GetLocalAlignment("エルメスのバッグ", "エコバッグ", config) # => "バッグ"
今回の例は (3, 3, 2) でうまくいきましたが、実際に入力と出力の組み合わせを眺めると、ペナルティの値はマッチの得点よりもかなり高くしておく必要があるのに気づきます。私たちの場合では、 (3, 10, 10) くらいが適切かなと手作業で探索して決めました。
プロジェクトに合わせた特別な拡張
さらにマッチングを改善する方法を考えてみます。今回のタスクでは、工夫して、典型的なスミス・ウォーターマン法をより課題に適するように拡張してみました。
config := util.NewLocalAlignmentConfig(3, 10, 10) GetLocalAlignment("イヴサンローラン", "イヴ・サンローラン", config) // => "サンローラン"

いま、スコアセットを(3, 10, 10) としたせいで、ねらいとしては イヴサンローラン が取れてほしいのに、先頭の イヴ の部分が切れてしまいました。これだと9文字中6文字しかヒットせず、閾値 0.8 とするとミスマッチになりそうです。獲得できるスコアを頭から考えてみると、先頭の2文字で6点を得てもギャップペナルティ10点を支払えないので切れてしまっているのがわかります。このように、スペースや中黒でミスマッチしてしまう場合をなんとか救ってあげられないでしょうか?
そこで、状態推移をするときに、各キューの先頭文字によって異なる点数づけをしてやるようにします。具体的にいうと、ある文字でのミスマッチを禁則にしたり、逆にある文字では許容するなどの設定を作ります。スペース や中黒 ・ によるミスマッチはいまのタスクでは頻出するのでペナルティ0点とします。次に、格助詞 のは新しい係り受けを作る言葉で、これをまたぐマッチングは文法上正しくないと言えるので取り除くとよさそうです。よって、 の によるミスマッチは禁則とし例外的なペナルティ例えば100点マイナスをつけます。しかも、 の による正しいマッチは依然として許容されるので、父の日 はマッチングに使用できます。
よって、こんな感じに関数を改造してやるとよさそうです。
type LocalAlignmentConfig struct { defaultMatchScore int defaultUnmatchPenalty int defaultGapPenalty int penaltyMap map[rune]int } // ex. // config := util.NewLocalAlignmentConfig(3, 10, 10, map[rune]int{ // 'の': 100, // 禁則 // ' ':0, // ノンペナルティ // '・':0, // }) // GetLocalAlignment("イヴサンローラン", "イヴ・サンローラン", config) => "イヴサンローラン" func GetLocalAlignment(s, t string, config *LocalAlignmentConfig) string

このようにして得られたローカルアラインメントと、それによってできる ローカルアラインメントの長さ / キーワードの長さ はLCSによるモデリングよりも有効に働きます。
最後に、この解決策の不利な点を説明しておきます。
- 処理は比較的重くなります。KMP法によって実装された
str.Containsが最悪ケースで計算量O(m+n)なのに比べ、LCSとスミス・ウォーターマン法は計算量O(mn)です。 - ハイパーパラメーターチューニングが要求されます。適切なスコアセットは手作業で見つける必要があります。また、そのような定数スコアセットの存在はコードの可読性やメンテナビリティをわずかに低下させると考えられます。
以下は、カスタマイズしたスミス・ウォーターマン法の実装例です。
type LocalAlignmentConfig struct { defaultMatchScore int defaultUnmatchPenalty int defaultGapPenalty int penaltyMap map[rune]int } // ex. // ``` // util.NewLocalAlignmentConfig(3, 3, 2, map[rune]int{ // 'の': 100, // }) func NewLocalAlignmentConfig( defaultMatchScore, defaultUnmatchPenalty, defaultGapPenalty int, penaltyMap map[rune]int, ) *LocalAlignmentConfig { return &LocalAlignmentConfig{ defaultMatchScore: defaultMatchScore, defaultUnmatchPenalty: defaultUnmatchPenalty, defaultGapPenalty: defaultGapPenalty, penaltyMap: penaltyMap, } } // ex. // config := util.NewLocalAlignmentConfig(3, 10, 10, map[rune]int{ // 'の': 100, // 禁則 // ' ':0, // ノンペナルティ // '・':0, // }) // GetLocalAlignment("イヴサンローラン", "イヴ・サンローラン", config) => "イヴサンローラン" func GetLocalAlignment(s, t string, config *LocalAlignmentConfig) string { // setting matchScore := 1 if config != nil { matchScore = config.defaultMatchScore } unmatchPenalty := 0 if config != nil { unmatchPenalty = config.defaultUnmatchPenalty } getPenalty := func(r rune) int { if config == nil { return 0 } penaltyValue, ok := config.penaltyMap[r] if ok { return penaltyValue } return config.defaultGapPenalty } sAsRunes := []rune(s) tAsRunes := []rune(t) sLen := len(sAsRunes) tLen := len(tAsRunes) dp := make([][]int, sLen+1) for i := 0; i < sLen+1; i++ { dp[i] = make([]int, tLen+1) } // fill the DP table highestScore := 0 highestI, highestJ := 0, 0 for i := 1; i <= sLen; i++ { for j := 1; j <= tLen; j++ { var diagonalScore int if sAsRunes[i-1] == tAsRunes[j-1] { diagonalScore = dp[i-1][j-1] + matchScore } else { diagonalScore = dp[i-1][j-1] - unmatchPenalty } dp[i][j] = maxOfFour( 0, diagonalScore, dp[i-1][j]-getPenalty(sAsRunes[i-1]), dp[i][j-1]-getPenalty(tAsRunes[j-1]), ) // find the highest cell if highestScore < dp[i][j] { highestScore = dp[i][j] highestI, highestJ = i, j } } } // construct localAlignment by backtracking localAlignment := []rune{} backtrack(sAsRunes, tAsRunes, &dp, highestI, highestJ, &localAlignment) return string(localAlignment) } func backtrack(s, t []rune, dp *[][]int, i, j int, lcs *[]rune) { // basecase if i == 0 || j == 0 { return } if (*dp)[i][j] == 0 { return } if s[i-1] == t[j-1] { backtrack(s, t, dp, i-1, j-1, lcs) (*lcs) = append((*lcs), s[i-1]) } else { if (*dp)[i-1][j] >= (*dp)[i][j-1] { backtrack(s, t, dp, i-1, j, lcs) } else { backtrack(s, t, dp, i, j-1, lcs) } } } func max(a, b int) int { if a < b { return b } return a } func maxOfFour(a, b, c, d int) int { return max(max(max(a, b), c), d) }
比較
ここまで紹介してきたアルゴリズムのPros / Consを比較します。
- 計算量の分析について、ユーザークエリの文字列長をm, キーワードの文字列長をnとします。また、キーワードリストの要素数をlとします。
機械学習モデルとの比較
機械学習システムには重いメンテナンスコストがかかるので、小規模なチーム向きではありません。また、学習済みモデルの不確かな挙動にもビジネスロジックを依存させたくありません。いっぽう、スミス・ウォーターマン法はただの動的計画法なので、メンテナンスコストは安いです。さらに、結果には確率的な要素が存在しないので、挙動は簡単に検証できます。
- 機械学習モデルによる実装を簡単に検討しましょう。文をあらかじめ形態素解析し、ベクトル化したあと、各キーワードごとのマルチクラス分類器にかける方法が考えられます。単語はWord2Vecのように意味を反映した仕方でベクトル化(embedding)すると、コーパスの学習次第では
クリスマスでXmasをマッチさせるような、今まで見てきた方法では不可能なマッチングができそうです。- 時間計算量としては、ユーザクエリを形態素解析したのち(これにはO(m2)が1回だけ必要です)、行列積を計算することになります。これがスミス・ウォーターマン法による実装より高速かは、行列の設計やその計算効率に依存するため、実験して確める必要があるでしょう。
- 欠点として、そのような確率的モデルの開発には、私たちの持っているキーワードリストに合わせた独自アノテーションや、モデルの新鮮さを検証し維持するための社内フローを整備する必要があります。
文字列マッチングアルゴリズム間の比較
検索ワードに対し、あるキーワードをマッチするときの文字列アルゴリズムの比較です。
| 方式 | 文字列完全一致 | 編集距離 | LCS | スミス・ウォーターマン法 | 拡張スミス・ウォーターマン法 |
|---|---|---|---|---|---|
| 時間計算量 | O(m+n) | O(mn) | O(mn) | O(mn) | O(mn) |
| 空間計算量 | O(m+n) | O(mn) | O(mn) | O(mn) | O(mn) |
| あいまいな文字列マッチング | できない | できる | できる | できる | できる |
| 長い入力文字列への対応 | 長さによらず一定の結果 | できない | 部分的にできる | 制御可能 | 制御可能 |
| ハイパーパラメータチューニング | なし | なし | なし | 必要 | 必要 |
| 文字ごとの考慮 | できない | できない | できない | できない | できる |
| 実装コスト | 標準ライブラリ | 動的計画法の自前実装 | 動的計画法の自前実装 | 動的計画法の自前実装 | 動的計画法の自前実装 |
- 文字列完全一致はKMP法による実装を想定します。
- 時間計算量について、どのやり方でも、最終的には各キーワードごとに上記のマッチングを行う必要があります。結果、文字列完全一致ではO(l *(m+n)), スミス・ウォーターマン法ではO(lmn)かかります。
- 空間計算量について、文字列完全一致以外はDPテーブルを確保するためメモリを多く使用します。いずれにしてもサーバで使用できるメモリに対して無視できるほど小さなメモリしか使用しません。
- 長い文字列の入力に対し、LCSでもうまくいくことがありますが、マッチング範囲が制御できないので偶然長い一致が取れてしまうことがあります。スミス・ウォーターマン法はハイパーパラメータを使ってマッチング範囲の制御を可能にしています。
- ところで編集距離はLCSと似た動的計画法で実装でき、計算量は上の通りです。
実際に使ってみて
サービス実装にあたっては、ギフトモールの上位検索キーワードリストを作成し、それらに対して正しい結果を返せているか、クオリティチェックを行いました。期待通りの成果にならないものについては、なぜ期待通りに振舞ってくれないかの分析を行いました。フォールバックを設定したり、キーワードリスト自体を増やすなどの対応も行いました。実際、スミス・ウォーターマンアルゴリズムを適用するアイデアは、この試行錯誤から生まれました。最後には、リリースできるクオリティに達したとチームで判断し、リリースを迎えました。
その後検索エンジンではこれを検索のたびに使っていますが、今の所ほとんどのクエリに対しお客さまを待たせない速度で動作しており、うまくいっていそうです。ただ、実際には検証しなくて良いキーワードは検証しないなどの細かい最適化を入れています。
細かく設定を調整できるので職場で非常に使い勝手が良いという印象です。特に、実際にサービスを運用しているとxxxのときにはyyyを当てたい、当てたくないというようなリクエストを社内から受けることが多く、それらを定数を変更するだけで対処できるのでとても嬉しいです。
今後のスケーリングについて、キーワードが現状の10倍になると必要な時間も10倍に増えてしまいます。そうなった場合には、キーワードを整理したり、違うマッチングアルゴリズムを考えたりする必要があります。
まとめ
古典的な文字列マッチアルゴリズムは、多少複雑に見えるとしても役に立つものです。この記事ではスミス・ウォーターマン法にもとづく、あいまいキーワード抽出を実装しました。第一に、この方法は表記揺れと長いユーザー入力の両方に対して頑健です。第二に、いくつかの特殊なルールを設定できるので、状況に合わせた柔軟性があります。というわけで、実際のビジネスシーンでも役立つテクニックだといえるでしょう。
ギフトモールでは、一緒に働く仲間を募集しています!
まずは一度話してみるだけなどのカジュアル面談も歓迎ですので、少しでも興味を持った方はお気軽に連絡ください!